Keymaker
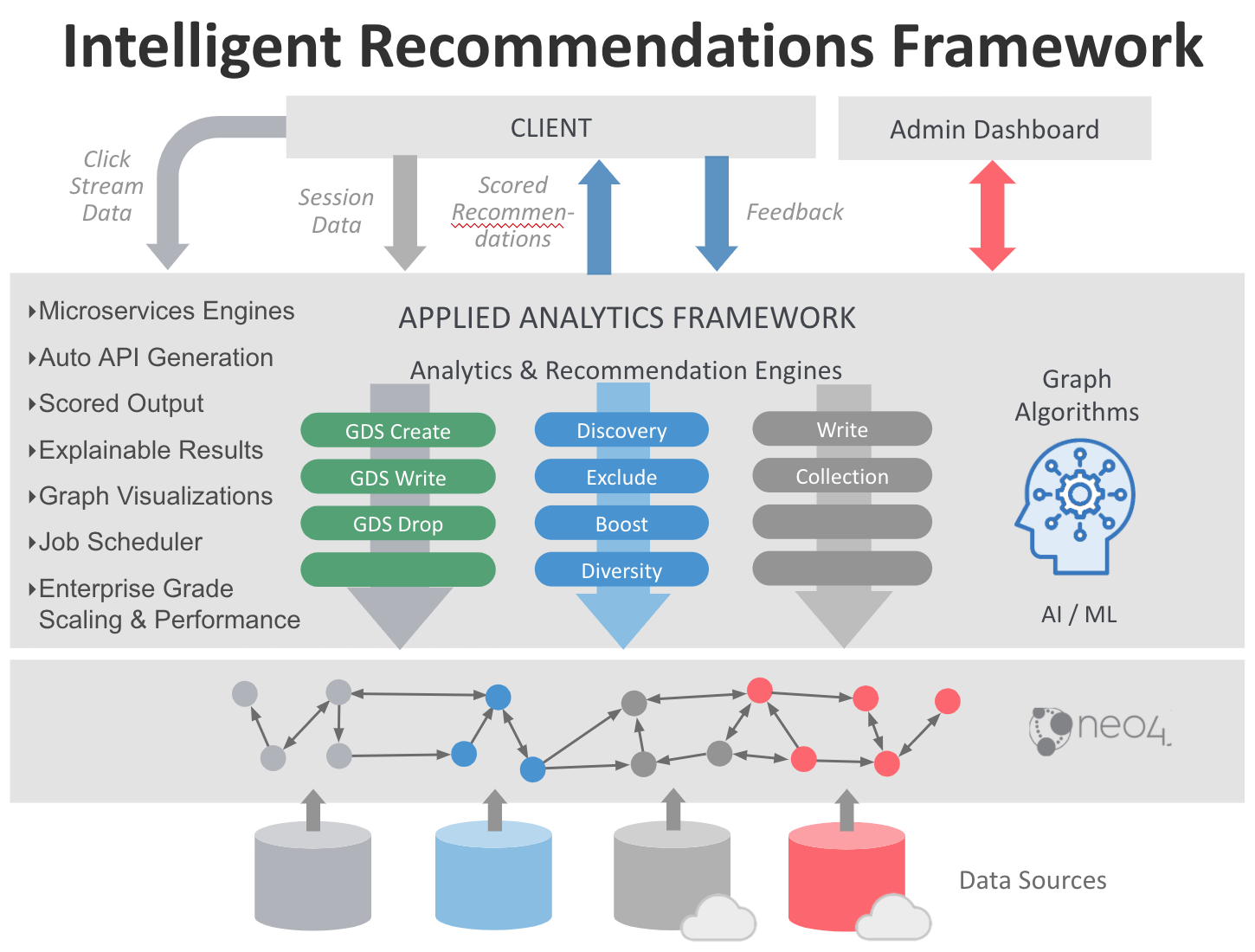
Keymaker, Neo4j’s Applied Analytics Framework, is a data model agnostic tool designed to help organizations operationalize their graph based analytical queries.
Keymaker includes an admin console where users can build out their analytical or recommendation pipelines, and exposes a GraphQL api where results can be accessed.
Important Concepts
Recommendation
A recommendation set is a list of score item pairs, and an additional optional details field.
Both the item and detail fields can be any type supported by Node.js and Neo4j and a score must be a numerical type.
The recommendation set is accumulated and scored using a cypher based analytical engine, built on top of Neo4j.
Analytical Engine
An analytical engine is a pipeline composed of different steps, called phases, which takes as input an arbitrary json object and produces a list of scored results or recommendations.
An engine must have a connection to a Neo4j database.
However, Keymaker is data model agnostic and can connect to any number of existing Neo4j Databases simply by providing the database url and credentials.
Each phase in the engine pipeline is defined using Neo4j’s Cypher query language.
There are two varying execution modes; server-side execution, where all phases are compiled into a single cypher statement and executed at once, and sequential execution, where each phase is executed independently one after another.
High Level Architecture
Keymaker has 3 components: the admin dashboard, admin API, and Engine API. The admin dashboard and API facilitate user interaction with the framework (i.e. database connection management, engine creation, and writing Cypher). The engine API connects with your Neo4j database and exposes an endpoint which executes the engine. The following diagram demonstrates this architecture.

Database Compatibility and Prerequisites
Keymaker supports Neo4j versions 4.4.x and 5.x. Core APOC procedures are required and come pre-installed on Neo4j Aura. To use the Graph Data Science Library in your Cypher pipelines, ensure it is installed as well.
Engine Phases
There are different types of phases, each with a specific purpose in the pipeline. Each phase has access to all of the engine inputs as cypher parameters.
Discovery Phase
A discovery phase is used to locate potential results or recommendations, giving each item an initial score. The first phase in each engine must be a discovery phase, but additional discovery phases may be included later in the list. A discovery phase can be any arbitrary cypher query which returns a list of records containing a recommendation composed of an item, score, and details field.
Boost Phase
A boost phase is used to modify the score of items previously discovered. A pipeline can have any number of boost phases. A boost phase is any arbitrary query which returns a single score value, which is in turn added to the existing score. Note that unlike Discover phase queries which are each run once, a Boost phase is run against each result or recommendation in the current list. The item in the current result or recommendation can be accessed from cypher using the keyword ‘this’.
Exclude Phase
An exclude phase is used to filter down the list of results or recommendations either by specifying which items to remove, or by specifying which items to keep and removing the rest. Like a boost phase, an Exclude phase is also executed against each recommendation in the list and returns a single corresponding value for each. If the value is null then the recommendation is removed from the list. Exclude phases can also be inverted where only the null values remain.
Diversity Phase
A Diversity phase is used to ensure that the recommendations in the list are heterogeneous over a specified attribute. A limit is chosen for the maximum number of items included for each attribute, prioritizing items with the highest score. The phase then executes a query which returns a single attribute value for each recommendation in the list and then returns the value of the attribute for each item, removing any items beyond the set limit.
Collection Phase
A Collection Phase runs before your pipeline and allows you to match on nodes or patterns in your graph and return them as a map.
The values returned in this map will be accessible later at any point in your pipeline using the $ syntax.
This becomes especially helpful if there are expensive traversals/computations which would otherwise need to be performed in multiple phases.
This phase must end with something that looks like: RETURN \{key: value} AS map.
Write Phase
A Write Phase allows you to perform analysis on your graph and write back results.
This phase should have no RETURN
statement.
GDS Create Phase
A GDS (Graph Data Science) Create Phase allows you to use gds.graph.create or gds.graph.create.cypher to create an in memory graph.
This phase should have no RETURN statement but you will need to YIELD something after the create procedure.
GDS Write Phase
A GDS Write Phase allows you to use gds.<algo>.write
to write back to Neo4j or gds.<algo>.mutate to update your in memory graph.
You may optionally use gds.<algo>.stream to write results back manually with Cypher.
This phase should have no RETURN statement but you will need to YIELD something after the create, mutate or stream procedure.
Admin Console
There are different types of phases, each with a specific purpose in the pipeline. Each phase has access to all of the engine inputs as cypher parameters.
Database Connection Monitoring
Keymaker tracks which databases are up and running and can be reached by the framework. It provides relevant information such as the database version and licenses, and ensures that all necessary plugins and procedures are present.
Active and Inactive Phases
Keymaker allows the user to toggle the phases of an engine on and off in order to analyze the impact that each has on the results and performance of the engine.#
Admin API
Keymaker utilizes two GraphQL APIs. The first is called the Admin API.
This API is used to perform all the CRUD operations on your engines and database connections.
It also handles user management and role based access control. The API can also be used to bypass the admin console and interact with the Keymaker database directly.#
Engine API
The second API is called the Engine API. The sole purpose of this API is to handle client requests. When a request is received the API will build the specified engine and execute it against its linked database connection (selected upon engine creation).
Recommendations/Analytics can be computed in two modes, either incrementally where phases are run independently, or they can be compiled into a single query and executed all at once. Each call to this API will return a list of json objects. Each json record contains the recommended item (some entity in your Neo4j database), a score associated with that item, and another json object which may contain other arbitrary information about that particular recommendation/analytics.
The engine API can be accessed via any http client.
The primary endpoint is called runEngine and has 1 required argument and 7 optional arguments.
The engine API requires an API key to access any of its endpoints. Keys can be created by an Admin in the Keymaker UI by navigating to <your keymaker url>/keys. API keys must be included in request headers as follows {headers: {api-key: <your api key>}}. API keys may or may not have an expiration date. Make sure to save your api keys somewhere safe after it gets created
The schema definition is as follows:
runEngine(engineID: ID!, phaseIDs: [ID!] = [], params: JSON = {}, first: Int = 20, skip: Int = 0,
parallel: Boolean = true, concurrency: Int = 5, useCache: Boolean = true )As you can see engineID is required and the subsequent arguments are optional and have default values. Executing this inside a GraphQL query would look something like:
query {
runEngine(engineID: <your_engine_id>, params: {someParam: "value"},
first: 25, skip: 0, parallel: true, concurrency: 10) {
item score details }
}The runEngine endpoint will also allow you to run phases either individually or in a custom order of your choosing. All you have to do is pass in a list of phase IDs along with the engine ID’s. Executing this inside a graphql query would look something like:
query {
runEngine(engineID: <your_engine_id>, phaseID: [<your_phase_id>, <your_phase_id>,...], params: {},
first: 100, skip: 0, parallel: false ) {
item score details }
}Note: the values given to the optional arguments in these examples are just to demonstrate usage and are completely arbitrary.
You may provide parameters to your engine via the params object and access them from your cypher phases by prefacing the name of the parameter with a dollar sign (aka $).
You may also use the first and skip arguments for pagination.
The parallel and concurrency arguments determine whether queries will be run concurrently and to what extent.
Engine metadata is cached in the Engine API. This means once an engine is cached it no longer needs to be retrieved from the Keymaker database when runEngine is executed. This reduces overhead and improves performance. The useCache paramater can be set to false if you want to fetch the engine paramater’s from the keymaker database and not from the cache.
Keymaker will identify which queries to run concurrently based on the phase type.
In addition to the runEngine endpoint you also have access to the runEnginePerformance endpoint.
This can be used to simulate multiple users running your engine.
The schema definition is as follows:
runEnginePerformance(engineID: <your_engine_id>, params: {}, first: 25, skip: 0,
numUsers: 10, sleep: 500)The engine API also allows you to run an engine as a scheduled database job. The associated endpoints are as follows:
runBatchEngine(engineID: ID!, timeIntervalSeconds: Int!,
params: JSON = {}, delaySeconds: Int = 0): BooleanisBatchEngineRunning(engineID: ID!): BooleancancelBatchEngine(engineID: ID!): BooleanFinally, here’s an example of a request to the engine API from a client application (javascript) using the http client Axios.
export const getSomeRecommendations = async () => {
const res = await axios .post("https://<IP or domain name>/graphql", {
query: "query { <your graphql query> }",
},{
headers: {
"api-key": <your keymakerApiKey>
},
})
.catch((err) => console.log(err));
return res.data ? res.data.data.runEngine : [];
};Performance Optimization
Starting with the Keymaker 6.0.0 release available here,Keymaker now supports a new feature called "Parallel Runtime" This feature was introduced in Neo4j version 5.13. The parallel runtime helps run complex read queries more efficiently. To use this feature, your database must support parallel runtime. You can enable it when you edit an existing database connection and engine. For it to work, both the database and the engine must have the parallel runtime turned on.
However, parallel runtime should not be enabled in the following cases:
-
If your engine queries use non-thread-safe APOC procedures
-
If your workflow involves writing back to the database
-
If you plan to run GDS workloads
You should not enable parallel runtime for engines which contain the Cypher Write Phase or GDS phases, as parallel runtime is unsupported for GDS workloads and write queries. For more details, visit the Neo4j Parallel Runtime Documentation.
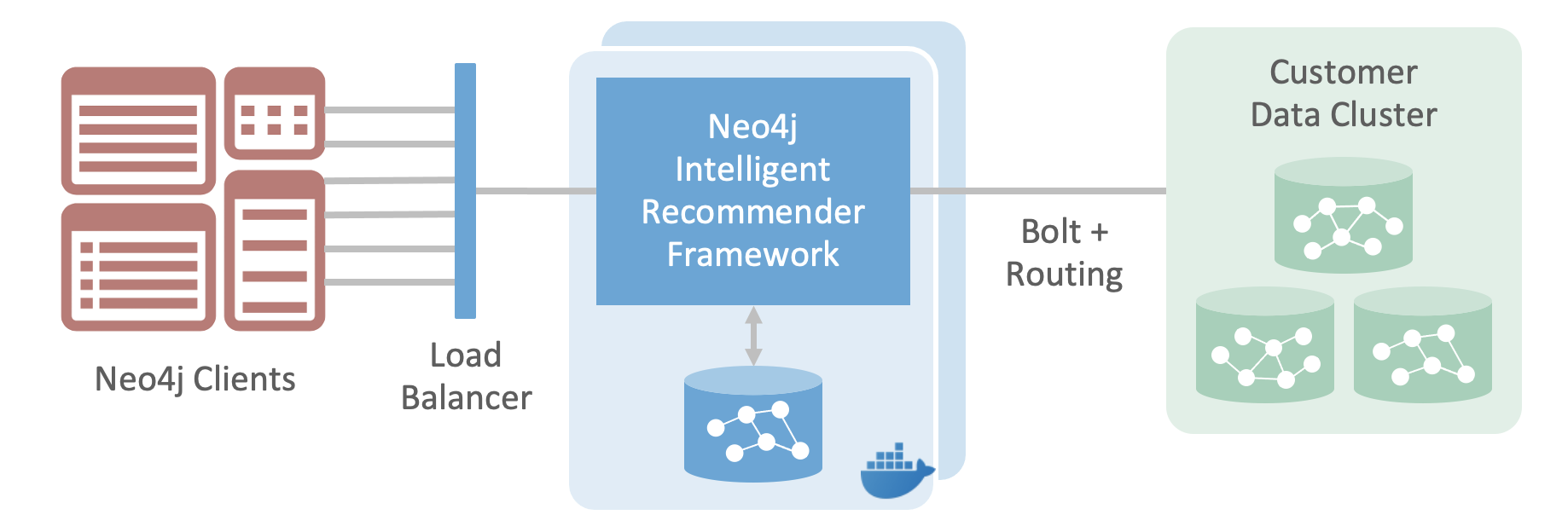
Scaling and Clustering
You can achieve greater throughput with Keymaker by using it with a Neo4j cluster and setting up multiple Keymaker instances pointing to the cluster. The Neo4j database and Keymaker can be scaled independently as needed. A load balancer in the deployment environment would need to load balance between all configured Keymaker installations.
During Engine execution Keymaker is stateless, therefore providing the ability to scale horizontally by installing on additional machines. Keymaker consists of an Administration UI, Adminstration API, internal Neo4j database, and a Engine API. Only the Engine API would need to be installed and configured separately on each additional machine, the other pieces can remain on the main Keymaker machine and be shared by each additional Engine API install.
The image below shows 2 installations of Keymaker - pictured here as the Neo4j Intelligent Recommender Framework - behind a load balancer. Each of the Keymaker installations points to the same Neo4j cluster.
Solutions Workbench Integration
You may also leverage the Solutions Workbench visual Cypher Builder to create Keymaker pipelines.
To use this integration first attach a data model to your Keymaker engine (either during engine creation or by clicking the edit button on the engine page). You will only have access to data models you also have access to in Solutions Workbench. Next, click the 'edit visually' button in the phase card drop down menu. This will launch the Solutions Workbench visual Cypher Builder. Build your cypher query (for more info on the Visual Cypher Builder click here) and click the 'Update Keymaker' button in the top right corner of the screen.
This will update the Keymaker phase from which you launched the Cypher Builder.